- All the SharePoint Content Source information like site, crawl rules,etc... is stored in Search Administration DB in SQL Server
- And the same information (start address) is replicated in to the registry of crawl servers.
- When search administration starts the full crawl the copies the registry from crawl server to the queue in the crawl database (in sql server) and admin component will assign crawl server based on the registry information and start address information and then crawl will get started.
- Crawl Server Determines what protocol to be used based on the type of site mentioned in content source information
- Then crawl server will start crawling the content ,based on the I filters systems crawls the content ,at this point data is crawled but not indexed so indexing engine will index the crawl content and make it available in full text indexed data.
- Now this indexed data is copied to that query server designated in search service application and if we have mirror index partitions the data is copied to the mirror server.
- When copy of indexed data is moved to query server, the data is deleted from crawl server
- Then finally crawl server will send the details like url,meta data information to the crawl and property databases by using http connector. This is the final state of crawling.
Sunday, September 15, 2013
SharePoint - Search Crawl Sequential Process
Subscribe to:
Post Comments (Atom)
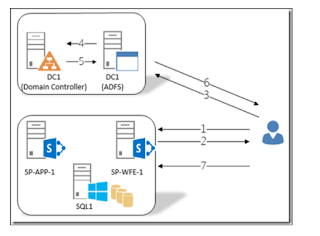
SharePoint 2013 - ADFS - Configuration
The main objective of this post is to provide detailed configuration steps on how to set up SAML Authentication for SharePoint 2013/2016 w...
-
This post talks detailed high level steps that are to be implemented for the configuration of IRM in SharePoint 2013 on premises for bot...
-
 The main objective of this post is to provide detailed configuration steps on how to set up SAML Authentication for SharePoint 2013/2016 w...
The main objective of this post is to provide detailed configuration steps on how to set up SAML Authentication for SharePoint 2013/2016 w...
No comments:
Post a Comment