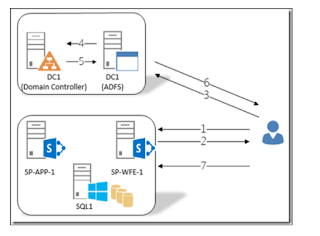
Crawling SharePoint sites using the SPS3 protocol handler
When you setup your
content sources in a Microsoft Office SharePoint Server (MOSS 2007), you have a
few options to choose from: SharePoint Sites, Web Sites, File Shares, Exchange
Public Folders and Business Data. When you use the SharePoint Sites option, you're
instructing the indexer to crawl a WSS web front end and you will use sps3://
as the prefix for your start address. This tells the crawler to use a
SharePoint-specific protocol handler to enumerate the content and then grab the
actual items from the SharePoint server.
A common question
here is whether this uses some sort of RPC call into the SharePoint Web Front
End (WFE) server. The answer is "no". People asking the question are
usually trying to configure the firewalls between a indexer and a MOSS WFE and
need to know what TCP/IP ports they need to open. You should be fine with just
HTTP (or HTTPS, if your portal requires that). The SPS3 protocol handler uses a
web services call (using HTTP/SOAP) to enumerate the content and then uses
regular HTTP GET requests to get to the actual items. Crawling using the SPS3
protocol handler requires no RPC calls or direct database access to the target
farm. That's the main reason why this type of crawling is supported over WAN
links and has a good tolerance to latency.
If you want to
confirm this, configure two separate MOSS farms and have one crawl the other:
- Configure a new content source using Central
Administration, Shared Services, Search Settings, Content Sources, Add
Content Source.
- Specify SharePoint sites as the type and use
SPS3://servername as the start address
- Start a full crawl
If you have any
network monitoring hardware or software, you will notice that one the first
things the crawler will do is use the "Portal Crawl" web service at http://servername/_vti_bin/spscrawl.asmx.
The methods in this web service are EnumerateBucket, EnumerateFolder,
GetBucket, GetItem and GetSite. It is interesting to see how both
"Enumerate" methods will basically return just an "ID" and
a "LastModified" datetime, hinting at how SharePoint can do
incremental content crawls via this protocol handler... If you just point your
browser to that URL yourself, you can find the additional information about the
web service, including sample SOAP calls and the WSDL (as you get with any .NET
web service). At this point, I could not find much detail on this web service
beyond the actual class definition for
Microsoft.Office.Server.Search.Internal.Protocols.SPSCrawl.

No comments:
Post a Comment